- Server 1: historie a záměr
- Server 2: koncept UPS
- Server 3: realizace UPS
- Server 4: komponenty UPS
- Server 5: návrh HW pro server
- Server 6: Konstrukce a chlazení
- Server 7: software
- Server 8: zkušenosti
- Server 9: upgrade a zašifrování RAID pole
- Server 10: automatické odemknutí zašifrovaného pole
- Server 11: přechod na RAID6
- Server 12: UPS baterie umřela
- Server 13: upgrade CPU
- Síť
- NAS a zálohovací server
- Server 14: Výměna disku za pochodu
- Server 15: využití zahálejícího výkonu
- Server 16: výměna chladiče a poučná zkušenost
- Server 17: Virtualizace serveru
- Server 18: Racková skříň a montáž
- Server 19: Spuštění rackového serveru
- Server 20: konečně SAS řadič a další výzva
- Server 21: Zálohy reloaded
- Server 22: Výměna základní desky
- Server 23: Rack
- Server 24: NAS HDD do šrotu?
- Server 25: zkušenosti s ročním provozem
- Server 26: Migrace Raid1 pole
 V prázdninovém opojení, v relaxačním týdnu a deštivém počasí, jsem si řekla, že na SMR disku v R1 poli se vzrůstajícím počtem realokovaných sektorů spustím smartctl -t long test, který provádí čtení celého disku. Protože mírně snižuje dostupnost pole a především, protože existuje riziko, že odhalí problémy, které byly dřív neviditelné a bude třeba je řešit.
V prázdninovém opojení, v relaxačním týdnu a deštivém počasí, jsem si řekla, že na SMR disku v R1 poli se vzrůstajícím počtem realokovaných sektorů spustím smartctl -t long test, který provádí čtení celého disku. Protože mírně snižuje dostupnost pole a především, protože existuje riziko, že odhalí problémy, které byly dřív neviditelné a bude třeba je řešit.
Test našel další vadné sektory, které označil za Pending a Offline uncorrectable. Čili ten disk zjevně odchází do věčných lovišť, na pole už se nemohu tak spolehnout, i když se zdá, že pracuje. Pracuje mi i smartd, který mi poslal mail:
The following warning/error was logged by the smartd daemon:
Device: /dev/sdg [SAT], 8 Currently unreadable (pending) sectors
No nic, čas mám, pole zruším trochu dřív, než jsem předpokládala.
Migrace na nový disk a zrušení pole
Plán byl jednoduchý: vytvořím si na produkčním R6 SSD poli nový disk, svěřím jej VM se Sambou. V přechodném stavu tak tenhle VM uvidí oba disky – staré 5TB R1 SMR pole a nový prázdný disk. Na ten nový disk překopíruju data z původního R1, pak upravím konfiguraci Samby a R1 z LVM odstraním. Fyzicky jsem staré Raid1 pole odstranit plánovala někdy v budoucnu.
Na hlavním Raid6 poli z šestice SSD mám luks, pak lvg VG1 a ještě přes 2TB volného místa. Na něm jsem vytvořila nový LVM:
lvcreate -L 2T -n lvMedia VG1
Nový virtuální disk jsem svěřila VM, který má na starosti NAS služby. V konfiguraci stroje jsem prostě vytvořila nový záznam pro daný disk. A pak jsem virtuál restartovala.
 A začaly se dít věci: do virtuálu se nešlo přes SSH přihlásit, ačkoliv na síti byl. Přihlásila jsem se do toho rozbitého VM přes VNC konzoli a zjistila, že selhal mount disku na původním RAID1 poli. Proč? Ještě se s ním přece nic nedělalo. V konfiguraci virtuálu žádný problém nebyl, stroj viděl všechny svěřené disky, včetně toho 5TB, který se ale nemountnul, i nového LVM 2TB nenaformátovaného disku.
A začaly se dít věci: do virtuálu se nešlo přes SSH přihlásit, ačkoliv na síti byl. Přihlásila jsem se do toho rozbitého VM přes VNC konzoli a zjistila, že selhal mount disku na původním RAID1 poli. Proč? Ještě se s ním přece nic nedělalo. V konfiguraci virtuálu žádný problém nebyl, stroj viděl všechny svěřené disky, včetně toho 5TB, který se ale nemountnul, i nového LVM 2TB nenaformátovaného disku.
Zkusila jsem starý disk mountnout ručně, a chyba, prý EXT4-fs error ext4 find extent… Což znamená poškozenou hlavičku fs, špatné. Takže ten načatý HDD přece jen zlobí, a to hodně. Naštěstí se to dalo spravit: v hypervizoru jsem zavřela luks kontejner nad raid1 polem (luksClose), ten selhávající HDD z raidu 1 jsem prostě vykopla:
mdadM /dev/md1 –fail /dev/sdg, pak –remove.
Server mi poslušně poslal zprávu:
A Fail event had been detected on md device /dev/md/1.
It could be related to component device /dev/sdg1.
Faithfully yours, etc.
P.S. The /proc/mdstat file currently contains the following:
Personalities : [raid1] [raid6] [raid5] [raid4] [linear] [multipath] [raid0] [raid10]
md1 : active raid1 sdg1[0](F) sdi1[2]
4883637440 blocks super 1.2 [2/1] [_U]
bitmap: 0/37 pages [0KB], 65536KB chunk
Pak jsem znovu otevřela luks kontejner nad tím degradovaným R1 polem, restartovala virtuální stroj s NAS, a vida, pole se nechalo namountovat. Moje teorie je, že Raid1 se špatným diskem tedy úplně v klidu čte a vrací data z vadného disku – a vadné sektory zasáhly do samotné fs tabulky. Dává to logiku – žádná parita, prostě co mu dřív přijde, to bere. Raid6 je v tomto ohledu spolehlivější, ale k tichému poškození dat i tak dojít může.
Následně jsem ve virtuálu mountla i nový logický 2TB disk, naformátovala jej jako ext4 a přenesla jsem na něj veškerá data z degradovaného raid1 pole. To trvalo několik hodin a server (nejspíš SAS řadič) se u toho dost zapotil:
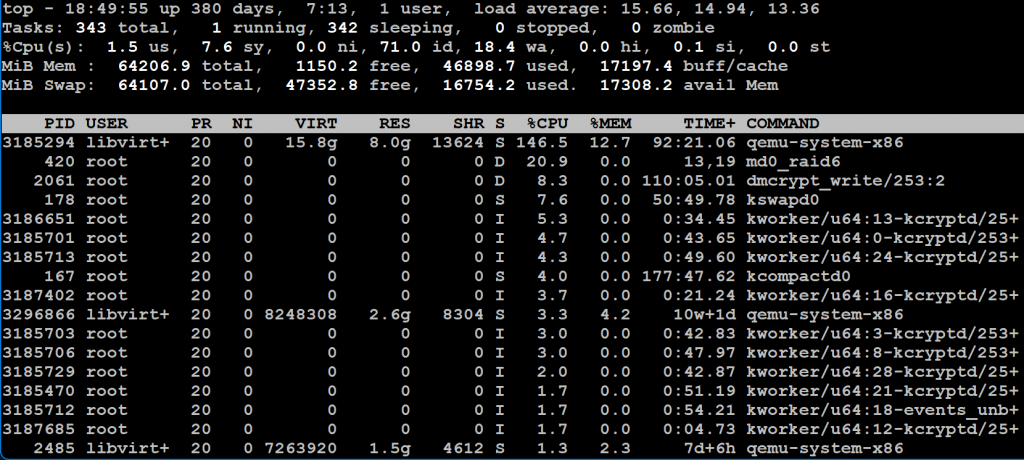
Na výkonu serveru to bylo i znát – načítání nekešovaných stránek trvalo o poznání déle.
Následně jsem upravila fstab VM tak, aby se už připojoval jen nový LVM disk tam, kam původně to původní raid1 pole. Z konfigurace VM jsem odstranila celé to raid1 pole, poslední testovací restart VM – ten si dal trochu načas. Vše se ale namapovalo podle očekávání, starý raid1 pole už ve virtuálním stroji nemám.
A LVM disk s audiovizuálními soubory je téměř plný:
/dev/vdc 2.0T 1.8T 87G 96% /mnt/meDisk
Ale to spraví další disky v pozicích, které se uvolní po SMR discích. Pole raid1 stále na hypervizoru jede, je degradované, nikde není použité, a uvolnila se mi hotswap pozice. Mám v šuplíku jeden nepoužitý 1TB disk, dám jej tam a přidám jej jako další disk.
Zvětším mdadm pole a obalující luks kontejner.
Zvětším LVM lvMedia o nové 1TB.
Ve virtuálním stroji zvětším filesystém.
Poznámka z budoucnosti: ano, volný 1TB jsem měla, byl to Verbatim Vi550 S3, který mi jednou mdadm vykopnul z pole. Nahradila jsem jej novým diskem, ten Verbatim se ale tvářil funkčně, tak jsem jej příležitostně používala na off-site zálohy. Ten disk byl ale určitě nějak vadný, protože občas fungoval, občas ne, problémy jsem ale přisuzovala externímu SATA->USB case. Zkusila jsem tento disk vrátit do serveru – server jej sice zobrazil v lsblk, ale po přístupu k němu utilitou fdisk se ze systému ztratil. Ten disk byl sice ještě v záruce, ale kupovala jsem jej na CZC, které se nechalo zrušit tržištěm, se kterým nechci mít nic společného, takže reklamovat jej nebudu…
Později, až koupím první 2TB disk, to staré Raid1 pole úplně zruším, a provedu ty úkony ještě jednou, takže výsledkem budou 4TB k dispozici pro data filmů, fotek a muziky, které jsem původně měla na dvojici zrcadlených SMR disků.
No a v průběhu dalšího času budu pomalu nahrazovat ty 1TB disky za 2TB, což už bude asi ultimátní řešení mého datového prostoru.
Závěr?
SMR disk běžel nonstop 24/7 několik let. Asi dostal ťuka, nebo jsem měla smůlu na slabší kousek, protože už po roce zahlásil přemapované sektory. Druhý, o něco málo mladší, provoz zatím snáší bez problémů – veškerá data jsem z něj dostala, žádné vadné sektory. Takže výsledek je uspokojivý. Před čtyřmi lety nebylo kvůli ceně SSD pomyšlení na to, dělat podobné úložiště na SSD discích, a ani řešení serveru mi neumožňovalo postavit větší pole z malých SSD – tehdy jsem používala 500GB SSD.
No, a teď se zdá, že pole dosloužilo. Zbyl mi jeden plně funkční 5TB disk a druhý už nespolehlivý, použitelný jen na pokusy nebo na nějaké velmi nenáročné použití. A zbyl mi taky dobrý pocit, že mi oba velmi dobře posloužily.
Příběh měl o měsíc později ještě nepříjemnou dohru: Jednoho dne v neděli jsem při ranní kávě standardně nahlédla do emailů a na stav elektrárny, a koukám, že server nefunguje. Po připojení přes ssh jsem zjistila, že ačkoliv se vše zdálo funkční (všechny VM running, disky v pořádku), server má relativně vysokou zátěž a že staré degradované R1 pole nejde ani zastavit (mdadm –stop) a cryptsetup nešel na tomto R1 poli. Nešly zastavit (ani vynuceně) virtuály. Pak jsem zjistila, že se spustil standardní md check, který u produkčního R6 pole zamrznul na nějakých 60%, a že IO subsystém řadiče je úplně zahlcený – poslední hláška v logu qemu pro jednu z VM byla ERROR cluster xxxx refcount=0 reference=1, což může znamenat právě nedostupnost blokového zařízení.
Degradované R1 pole jsem odstranila ze všech konfiguráků (crypttab, mdadm.conf), disk jsem ze stroje vyndala a stroj jsem restartovala. Po restartu vše naběhlo správně, všechny VM nastartovaly a celý systém je funkční.
Není úplně jisté, co se stalo, ale je dost pravděpodobné, že to souviselo právě s mrtvým R1 polem v kombinaci s automatickou kontrolou polí a souběžnými zálohami a operacemi valcMonitoru – zdá se, že došlo k nějakém IO dead locku. Produkční Raid6 pole jsem zkontrolovala ručně, bez chyb, všechny disky v pořádku.
Takže ať už to byla příčina incidentu nebo nebyla, poučení je jasné – nenechávat v serveru mrtvolky, mohou potenciálně uškodit.